FrankenCode: Parsing Email Data Elements into a Database
It's not gonna be pretty, but I'm gonna stitch together some Python code components to make a functional thing. [maniacal laughter!!!]

The business problem to solve
I get daily grain market emails from which I need to extract prices, and drop into a database. This should be automated but I've been either paying for this data or performing manual data entry. I've been putting it off for a few years but it's time to tackle this project and make life easier for present and future me. I'm going to be using a combination of Python tools I've used before and tools I haven't used, and monstrously stitching them together to accomplish the thing I set out to accomplish.
First let me farmsplain the commodity grain markets. The market price of a bushel of corn can be found on Barchart. When a farmer brings their corn to the elevator, they will not simply receive the market price, they will collect the market price +/- the basis charged by the elevator. The basis is usually a below market, often in the neighborhood of $0.50 under the market price. If the market price is $4.50 for a bushel of corn, the farmer can expect to collect $4.00 from the elevator. When supply chains go wacky, sometimes this can "invert" and the elevator will pay the farmer a premium. The main thing to glean here is that this elevator basis varies from elevator to elevator, sometimes significantly.
Fluctuating markets make it beneficial for farm land lessors and lessees to draw up contracts as Flexible (or Variable) Lease Agreements (FLA). These can be set up many different ways but the basic principle is that the lessor gets a base payment plus a bonus based on crop productivity, which is calculated using an agreed upon percentage * yield * price. Setting up a FLA is a nice way to establish a fair return for both parties and avoid unnecessary haggling between parties each season.
Yield is easy to calculate. Take the bushels harvested from a given field divided by acres. A farmer will either have scale tickets, yield monitors, or both to determine this. Price is a different matter, and it's not always a straightforward process to obtain the data. Market data is easy, but elevator prices are a different animal entirely. In my case, the lease agreements stipulate that the price is to be calculated using the average cash price offered at a specific elevator local to me.
There are third party commodity market subscription offerings, but often they have a hefty price tag. I do subscribe to a free daily market email from the elevator stipulated in the lease agreements. If I were a rigid and disciplined human, I would simply enter this bid price into my database every day and tally up the average at the end of the year. Last year I sort of stayed on top of the manual process of collecting this data, but it's mid-November and I have done precisely none of this for 2021. But let's be real, even if I had the discipline to manually enter this data each day, I'd be annoyed that I hadn't gotten around to automating it, and there are countless other ways I'd prefer to spend those precious minutes.
Time to stitch together some Python code and automate this monstrosity.
The plan
The elevator bids go to my personal Gmail dumpster fire. They come from one of two senders at the elevator, and are formatted in HTML tables. I need to extract the cash (not future) corn bid, and the cash soybean bid for the day. I want the prices dumped into my financial accounting system for easy reporting. Notwithstanding the end-of-year reporting, which is out of scope for this article, this project has three main elements:
- Processing emails from a Gmail inbox
- Parsing HTML from emails to extract data
- Inserting extracted data into a database
Stitching stuff like this together can make for some ugly and sometimes not very readable code. But you know what? I don't care if the code is ugly and slow, as long as it does the job and isn't completely unmaintainable.
PART I: Processing email
Gmail allows access to inboxes via the IMAP protocol. Imbox is a Python library which allows for easy-to-use python syntax when accessing an IMAP-enabled mailbox.
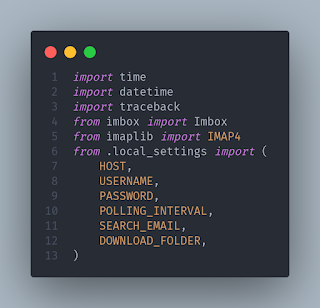
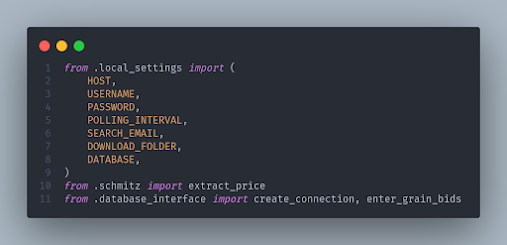
First, pip install imbox and set up the imports. I am using Audrey Feldroy's excellent cookie cutter package to set up my python project, so if you stash your credentials somewhere other than a .local_settings file, change your imports accordingly:
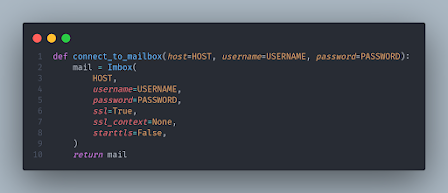
Next, we'll set up the connection to the mail client using imbox:
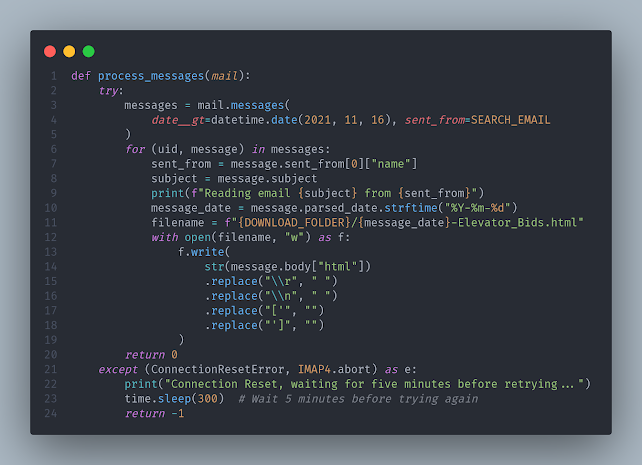
This code does stuff! Let's step through the important bits. It's all wrapped in a try/except block to fail gracefully if there are connection issues (lines 2, 21). Lines 3-5 filter the messages in the inbox. For my purposes, it's easiest to filter by date and sender email address. For now, I'm pulling a small sample. This gives me the emails I need to process. In lines 6-19, we loop through the messages and write the HTML from the message body into one file for each day. Lines 15-18 strips out useless newline and return carriage characters from the HTML.
Now let's put the aforementioned functions to work:
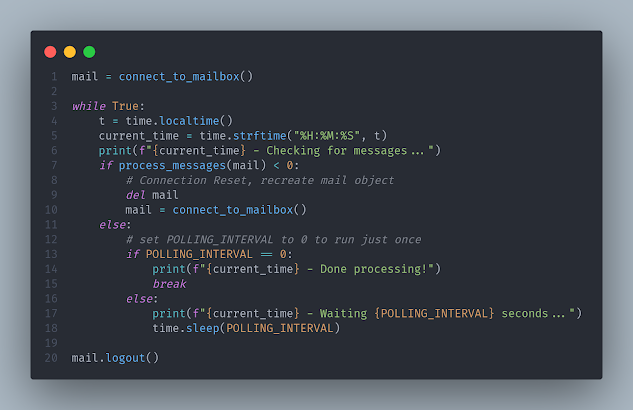
This is some code I modified from another project, so the loop isn't strictly necessary, but handy if you want to set up message polling. Line 1 creates the mail object, then line 7 calls the main process_messages function to extract the HTML. When done, you should have a folder full of html files.
PART II: Parsing the HTML
I think I could have accomplished this same thing with BeautifulSoup, but I chose Selenium for this project because... uh, I sorta forgot about BS. Also I've recently heard good things about Selenium and I wanted to try it out. If you're on Linux you'll need to ensure geckodriver is installed before trying to use Selenium. It needs this to launch Firefox. You'll also need to pip install (pip install selenium).
The rendered HTML from the email I want to parse looks like this:
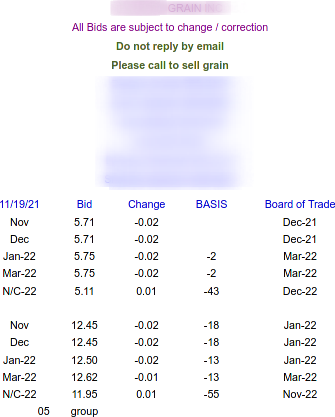
I want to extract the corn and soybean prices for November.
I had lots of help from StackOverflow to get started with this. I did clean up the find_elements functions (lines 27-28) though, which was find_elements_by_css_selector() before I switched it to the package maintainers' preferred new way to do it, importing By. Pat on the back for myself - good job, me. I changed the thing I copied from StackOverflow which I'm gonna say makes me a cut above the rest! 😆Mostly I just don't like warnings popping up in my terminal.
Anyway, the function started off really simple and I slowly began to realize after looking at some older emails that this needed to be more robust to handle some of the different scenarios.
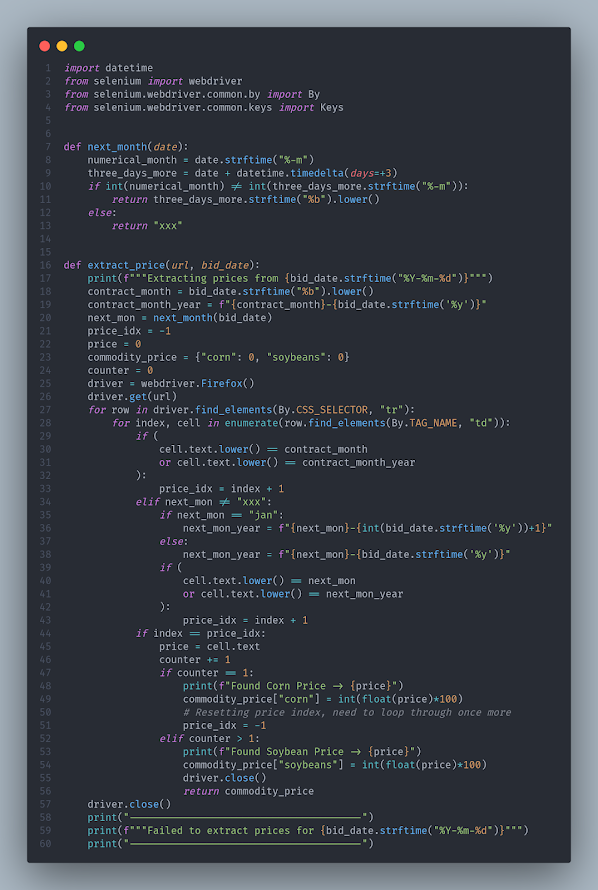
After refactoring this function a few times, I trimmed down the parameters (just pass in the URL/filename and an email date) and made it return a dictionary of commodity prices. The next_month function handles the scenario where the elevator contract flips to the next month at the end of a given current month. Grain elevator business quirk... idk. My database wants the value as an int to avoid the whole floating point thing, hence the conversions in lines 49 and 54. If this function can't parse out a valid price, it'll complain loudly in the terminal and return None. I tested this out extensively with some different valid and invalid input html, and it seemed robust enough for my use case.
PART III: Wrangle the data into the database
In parts I and II, we acquired the data we want. Now it needs a home. GnuCash is my accounting program of choice. It has an SQLite database backend, and we'll only be dealing with one table for this particular element, so it's not terribly complex. We could use an ORM for this but I think the simplest way to accomplish the goal here is to use the SQLite package built into python.
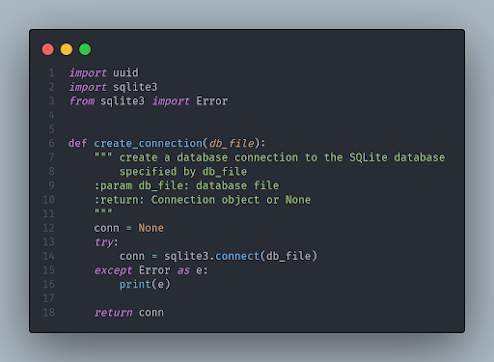
Let's connect! No need to reinvent the wheel here. SQLite Tutorial has what we need. This function is just fine. It connects to the database; let's use it as it is. The only thing I added to this code is the uuid import, which is required to generate a guid for GnuCash.
I borrowed more from SQLite Tutorial (lol, I even forgot to fix the docstring 😅) for the insert function, but I modified it heavily to suit my needs:
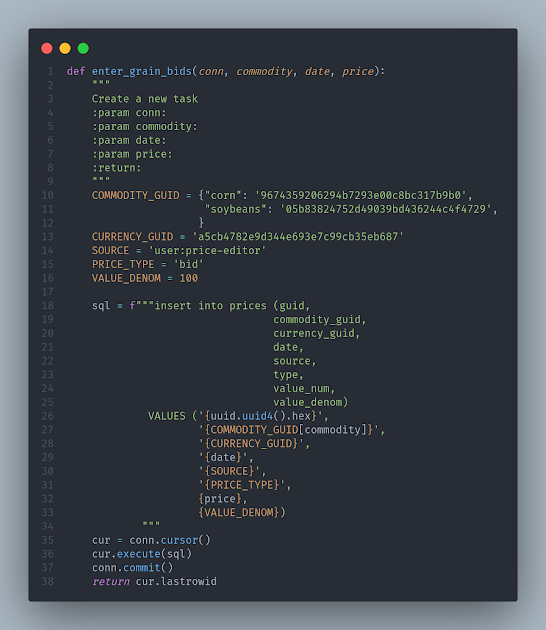
The goal of the enter_grain_bids function is to generate and execute a SQL Insert statement. It will take the connection object as a parameter, along with the commodity (corn or beans, in my case), date, and price. The CURRENCY_GUID, SOURCE, PRICE_TYPE, and VALUE_DENOM are static elements which will always remain the same per what GnuCash expects.
Instead of overthinking the modularization of this monster, let's just inline the grunty stuff into the email function from part I. In the time I've been writing this post, I've already done a fair amount of refactoring, there will be time for more. First, we need to pull in the database and extraction elements into the imports of the email processing file:
With the extract_price function and the database stuff accessible, we can add the necessary code in the main email processing loop:
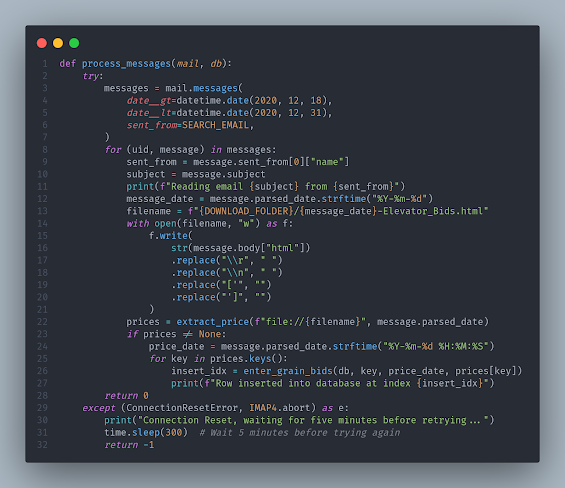
You may or may not notice the date filters are changing as I go. This is because I've been actually running this thing, and I'm trying to keep my date ranges manageable to avoid compromising the data. The newly added code in this function begins at line 22 with the price extraction. We'll iterate over the dictionary returned by the extract_price with the corn and soybean price values. We need to massage the date format a little bit before entering it (line 24), but everything else is ready to plug into the db.
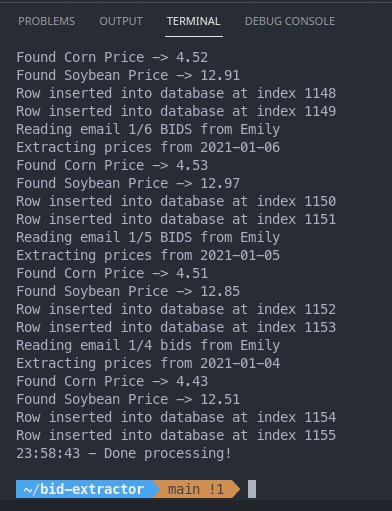
I've watched this thing chew through some of these emails and it's sort of neat to watch. It's not the fastest thing in the world because each time through the loop it has to open up an instance of Firefox. There's a way to do this headless, but why? Cheap entertainment! I'm spitting out some print statements so I can verify things look good on the fly. Here's some output:
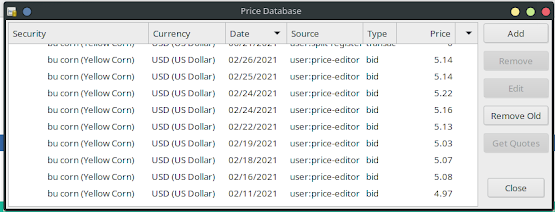
I look forward to running this script and watching the data automagically get injected into the GnuCash database rather than me copy-pasting and alt-tabbing myself into the insane asylum. Find the repo on the hub of git. Thanks for reading!
Comments
Post a Comment
"What you type into a comment box on the Internet
echoes in eternity."
- Gerald Ford